Cracking the Onion: A Beginner's Guide to Decoding Complex Japanese Sentences
(The Onion Architecture of Japanese)
前言
作为一个在英语学习上吃过甜头,并且热衷于解构语言底层逻辑的人,我在初学日语时也没吃过太大的苦头。我不喜欢死记硬背。我相信,如果一门语言能被几亿人顺畅地编译和运行,它必定有一套底层自洽的物理引擎。于是,我花了大量时间去查阅现代计算语言学(NLP)的资料,并结合我之前破解英语长难句的经验,试图给日语这门古老的语言重新写一份“标准化开发文档”。
在摸索中我发现了一个极其有趣的对比:如果说英语是“链表(Linked List)”——主干先跑出来,然后用介词和定语从句像链条一样向右无尽延展。那么日语就是一种典型的“洋葱模型(Onion Architecture)”——最核心的返回值(谓语动词)死死地压在最底层的句尾,而所有的修饰语、环境变量、触发条件,全部作为外壳一层层地向左包裹。
这篇文章是我写给自己的学习笔记,算是一次平等的经验分享,也是一套在实战中被证明极其高效的提分和速读方法。我会用极客最熟悉的“传参”、“封装”、“权限控制”等概念来重构日语的语法体系。希望能对那些厌倦了死记硬背的同路人有所启发。
第一章 日语语法入门
在开始破解那些让人头皮发麻的长难句之前,我们必须先统一基本概念。这就像在写代码前,必须先看懂官方的 API 文档。在这一章里,我会把构成日语的所有基础零件,揉碎了掰开来,把它们究竟是什么、为什么会存在、以及在系统里如何分类,彻底梳理一遍。
一、 基本数据类型(词类与四大动词引擎)
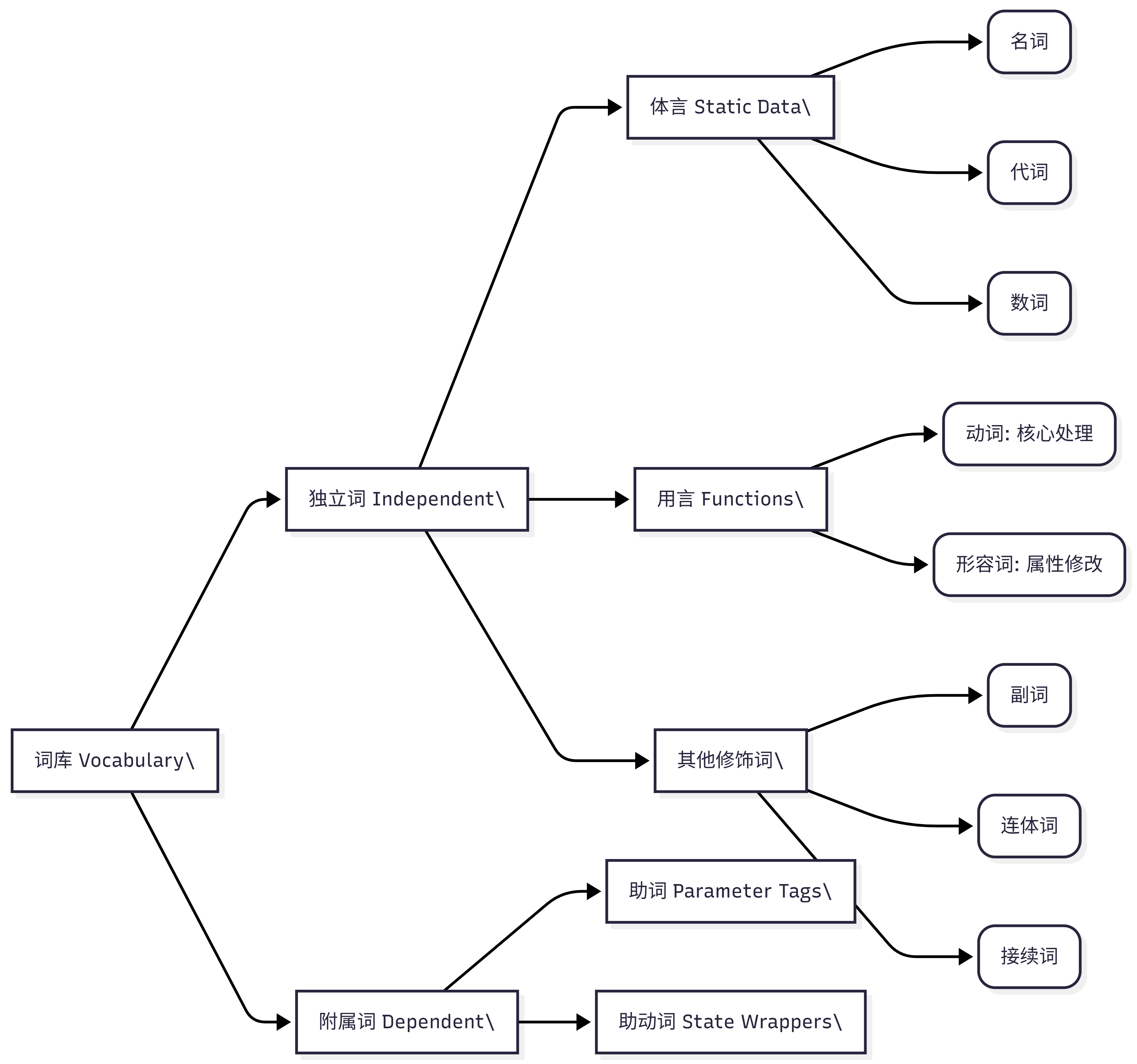
无论一句话多么复杂,拆到最细的颗粒度,无非就是一个个词汇。词类,就是这门语言最基础的“数据类型(Primitive Types)”。
你可能会问,为什么人类在发明语言时要搞出这么多种词性?其实这是为了信息处理的效率。
拿体言(名词、代词、数词)来说,它们在系统里充当的是静态数据对象(Static Data)。远古人类需要为现实世界中的实体(苹果、火把、我)进行命名,只有赋了值,我们才能在脑海的内存中随时调用它们。在分类上,体言包含了定义实体的名词、作为内存指针的代词,以及用于计量的数词。这三类词没有词尾变形,老老实实地充当数据,覆盖了 100% 的静态实体场景。
只有静态数据是不够的,我们需要给数据打上属性标签,这就是用言中的形容词。它存在的意义,是为了区分“大的猛兽”和“小的猛兽”。在日语中(覆盖率100%),形容词被分为了原生自带时态变形的“イ形容词(如大きい)”,以及由名词演化而来、需要借助外力的“ナ形容词(如便利だ)”。
而整个语言的绝对心脏,是用言中的动词。它是句子的核心处理器(CPU)。为什么最早的人类要发明动词?在农耕或狩猎时代,你根本不需要说出结构完整的句子。遇到老虎时,大喊一声“跑!”,或者遇到猎物大喊“杀!”,这个单一的动作指令就已经传递了最核心的求生信息。因此,动词是一切语言的主函数。
在传统日本语教育中,动词被简单粗暴地分为了“自动词”和“他动词”。但这套标准存在严重的分类 Bug。比如“见面(会う)”这个词,明明需要一个对象才能见,却因为不接宾语助词 を 被强行归为自动词。为了在实战阅读中不报错,我按“动词执行时必须的参数数量(配价/Valency)”,重新把动词划分为四大引擎。这套极客分类法能覆盖 99% 的核心业务动作:
- 一项动词(自动词): 这是一个单机运行的函数。它完全独立,只需要 1 个必需参数(主语 が)。比如“花开了(花が咲く)”。
- 二项动词 A(他动词): 这是一个需要摧毁或改变目标对象的动作。它需要 2 个参数:主语 が + 宾语 を。比如“我吃饭(私がご飯を食べる)”。
- 二项动词 B(补动词): 这是我原创的命名。这个动作不直接改变对象,但必须依赖一个方向或参照物才能跑通。必需参数是主语 が + 补语 に/へ/と/から。比如“我见朋友(私が友達に会う)”。
- 三项动词(补他动词): 这是一个资源转移的全家桶。通常表示“授受或信息传递”。必需参数包含主语 が + 补语 に/へ + 宾语 を。比如“我给老师发邮件(私が先生にメールを送る)”。
最后是附属词(助词与助动词)。它们本身没有独立意义,纯粹是语法胶水。因为日语是黏着语,不像英语那样靠位置定生死。日语靠的是贴标签(助词)和套外壳(助动词)。只要参数标签贴对了,词语在句子里的位置随便换,系统都能正常解析。
二、 六大句子成分
词类只是设计图纸,而句子成分则是这些词汇在具体运行环境(Context)中扮演的动态角色。
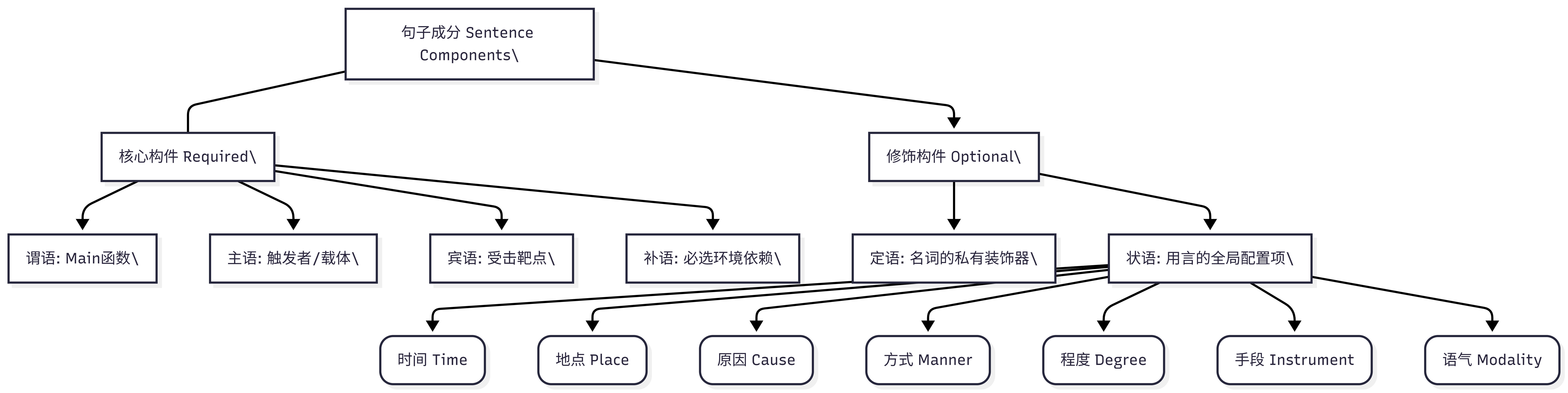
一句话能跑起来,必然有它的核心骨架。谓语就是这个绝对的 Main() 函数,因为它决定了整个程序最终是退出、报错还是输出结果,所以在日语里,谓语永远死死地钉在句号的前面。为了让这个函数运行,我们需要声明是谁触发了它,这就是主语存在的意义(用 は 或 が 标记)。如果这个动作具有破坏性,我们需要一个承受伤害的靶点,这就是宾语(用 を 标记)。而如果像“前往”、“送给”这类动作,没有目的地或接收人系统就会崩溃,这些必选的环境依赖,就是补语(用 に/へ/から/と 标记,覆盖了方向、对象、起点等 95% 以上的补语场景)。
骨架有了,但现实世界是复杂的,我们需要更精确的描述,这就诞生了修饰构件。
定语的职能极其专一,它永远只能放在名词的左边,充当名词的私有装饰器。它的存在是为了将内存指针精确到具体实例,比如把泛泛的“车”限定为“昨天买的红色的车”。它的分类覆盖率达 100%,无论是简单的代词(这个)、属性(美丽的),还是一个完整的句子(我买的),只要放在名词前,统统是定语。
相比之下,状语是一个极其庞大的体系。它永远放在动词或形容词的左边,充当全局运行环境的配置项。为什么要有状语?因为一个动作的执行,离不开具体的 Context。比如“部署代码”,我们需要交代时间(昨晚)、地点(在服务器上)、手段(用脚本)、程度(完美地)、原因(因为有Bug)。这些环境变量共同构成了状语的细分领域。此外,还有一种特殊的“陈述语气状语”(比如“也许”、“绝对”),它们就像预编译指令,只要出现在句首,句尾必定会绑定相应的推测或否定后缀,形成强校验。
三、 五大基本句型
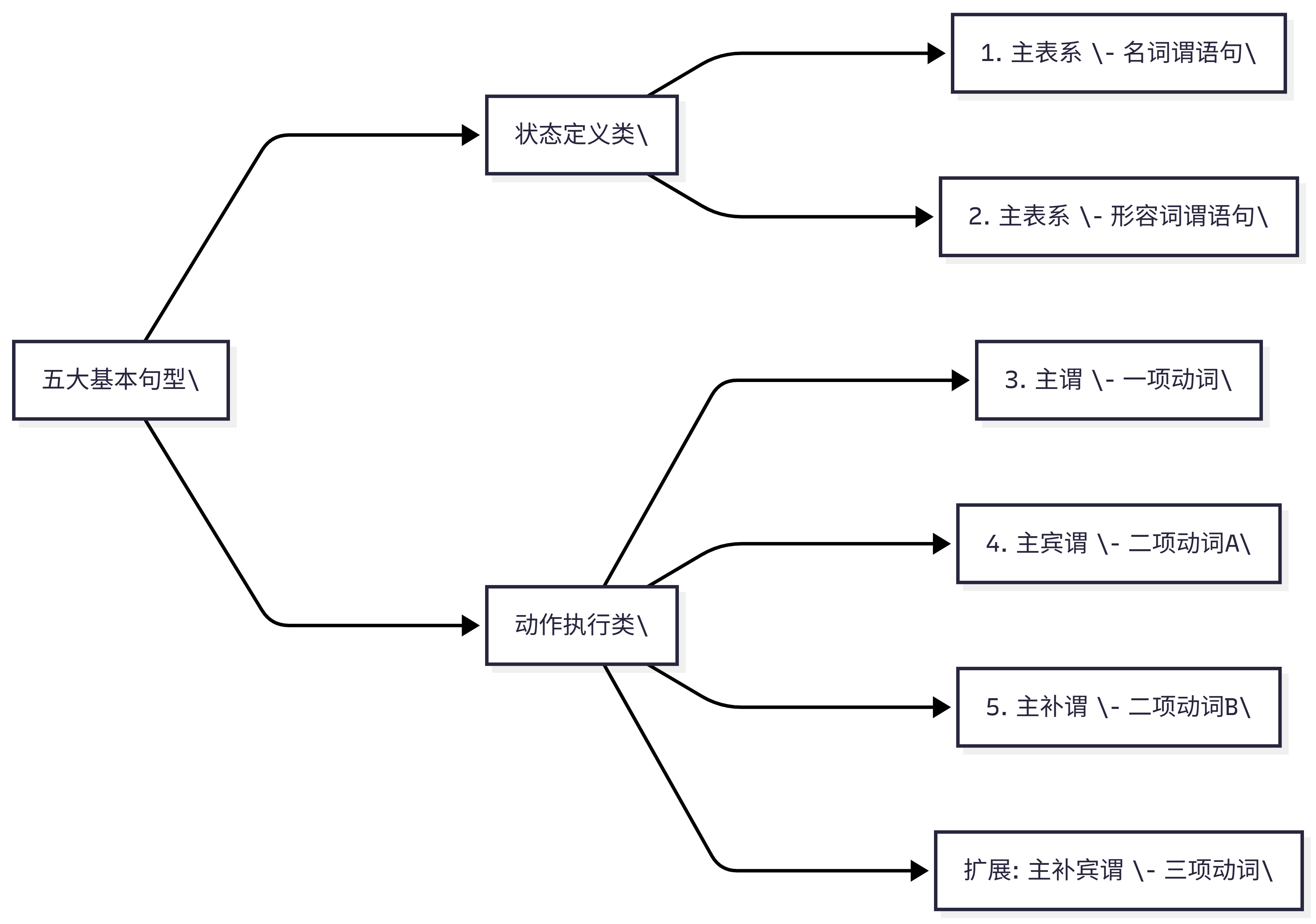
五大基本句型是所有日语句子的底层骨架(Architecture Templates)。无论一句话被那些疯狂的定语和状语拉到多长,只要你把修饰语全部剥离,剩下的主干必然落在这五类之中。
为什么要梳理基本句型?因为找准了它,你就能在一秒钟内抓到这句话的核心业务逻辑,不被挂件干扰。前沿的日本语语言学曾提出“判断、描写、叙述”三大句型,但我认为这种分类颗粒度太粗。基于前文的“状态”与“四大动词引擎”,我归纳了覆盖 100% 日语简单句核心骨架的五大句型。
这套模型非常直观:
- 如果核心逻辑是定义对象(A is B),那就是句型 1:主表系(名词谓语句)。格式是 [主语] が + [名词+だ],比如“他是工程师”。
- 如果核心逻辑是描述属性(A's property is B),那就是句型 2:主表系(形容词谓语句)。格式是 [主语] が + [形容词],比如“工具很方便”。
- 接下来的动作执行类,完全对应了我们的四大动词引擎:
- 句型 3:主谓。 引擎是一项动词,完全独立运行(系统运行)。
- 句型 4:主宾谓。 引擎是他动词,带着受击靶点 を 运行(我写代码)。
- 句型 5:主补谓。 引擎是补动词,带着方向/对象依赖 に 运行(数据到达服务器)。
- 以及最丰满的扩展句型:主补宾谓。 引擎是三项动词,包含了主语、接收人 に、转移物 を(他给团队分配任务)。
(注:为了不破坏核心骨架的纯粹性,我没有在上面列出 [主题] は。在实际运行中,任何句型的最前方都可以随时插入这个全局变量声明。)
四、 并列句(并发线程)
当我们想在一次输出中,陈述两个平级且互不干涉的事件时,基本句型就不够用了,我们需要引入并列句。你可以把它理解为程序里的并发线程(Concurrent Threads)。
在日语里,要拉起两个并发线程,方法分类很简单:
- 硬连接(使用接续词): 两个句子用句号断开,物理隔离,中间用一个接口词(如:そして、また、しかし)桥接。例如:“他是个优秀的工程师。而且,他还懂设计。”
- 软连接(中顿法): 不用句号,直接将前一个线程的核心谓语变成 て形 或 连用形,无缝挂载下一个线程。例如:“他是个优秀的工程师并且懂设计(エンジニアで、デザインもできる)。”
五、 三大从句(嵌套模型)
当我们需要传递的信息极度复杂,简单的形容词或副词参数已经不够用了怎么办?我们就把一个“包含自己主谓宾的完整句子”进行降维打包,变成一个巨大的组件,嵌入到外层的主句里。这就是从句(Subordinate Clause)诞生的根本原因——为了实现逻辑的嵌套。
日语的从句系统和英语截然不同。英语靠 that, which 往后甩,而日语的从句(置信度100%)全部是“前置包裹”的。

1. 名词性从句 (The Object Wrapper)
- 是什么: 给完整句子套上一个外壳,把它变成一个巨大的名词块。
- 为什么: 因为主干句型的参数位(主宾补)只接收名词类型的数据。
- 怎么分类: 依靠形式名词 こと 或 の 进行封装。封装后,可以接 が 做主语,接 を 做宾语。比如:“我知道 [他昨天偷偷修改了代码] + こと”。
2. 形容词性从句 / 定语从句 (The Left-Decorator)
- 是什么: 直接修饰名词的句子级组件。
- 为什么: 现成的形容词无法描述“昨天熬夜修好的”这种复杂事件属性。
- 怎么分类: 极其暴力。日语里不需要任何引导词,把你写好的完整句子,原封不动地拍在目标名词的左边即可。比如:“[昨天我熬夜修好的] Bug 又报错了。”
3. 副词性从句 / 状语从句 (The Logic Controller)
- 是什么: 挂载在主句前面的逻辑触发器。
- 为什么: 为了规定整个主函数运行的宏观环境或触发前提。
- 怎么分类: 它的分类覆盖了几乎所有的逻辑关联场景。只要在句子末尾加上特定的逻辑接续助词,它就变成了状语从句。
- 条件 (If/When): 用 ば、たら、と、なら 打包。比如:“[一旦报错たら],就去查日志。”
- 原因 (Because): 用 から、ので、ため 打包。比如:“[因为规范变了ため],所以重构了代码。”
- 让步/转折 (Although): 用 のに、ても、が 打包。
- 时间/目的/程度/方式: 用 とき、ために、ほど、とおり 等进行精准控制。
第二章 破解长难句指南(剥洋葱算法)
理解了第一章的组件和架构,你会发现一个残酷的真相:日语之所以长得让人绝望,全是因为它的“定语从句”是无限向左延展的,而各种“状语从句”则一层一层地把主句推向了深渊。
对于英语长难句,我们用“左二右六”顺藤摸瓜,找后置定语。而对于日语,因为它的逻辑是反向嵌套的,我总结了一套“剥洋葱(Peeling the Onion)”算法。这套算法是逆向工程的极致体现。
不要管句子有多长,只要机械地执行以下三步,10秒内看懂任何变态长难句。
Step 1: 直奔句号,剥离外壳,锁定主函数
面对长难句,千万不要从左往右读,这会让你在嵌套堆栈中内存溢出。
你的目光必须直接跳到最后一个标点符号的前面。
先看句末:把表示情绪、推测、时态的词(如 ~かもしれない、~べきだ、~た)像剥洋葱皮一样砍掉,这些只是态度或时间戳,不影响事实本体。
剥到最后,露出来的那个核心谓语(动词/形容词/名词だ),就是整句话的“主函数”。
通过它,你瞬间就能断定这句话属于哪种基本句型。
Step 2: 根据“动词配价”,逆向 Fetch 参数
主函数明确后,脑海中立刻调出我们在第一章设定的“四大动词引擎”文档:
- 如果是“他动词”,向左去扫带 を 和 が 的名词。
- 如果是“补他动词”,向左去扫带 が、を、に 的名词。
- 注意机制: 日语极度喜欢省略主语(Null-Subject)。如果你往左扫不到 が,说明主语要么是“我/你”,要么被存放在上一句话的全局变量 は 里了。直接脑补代入即可。
找到了这几个参数,直接提炼出主干,句子的核心业务逻辑就已经被你拿下了!
Step 3: 归类碎片(打包定语和状语)
主干抽离完毕,剩下的长篇大论怎么办?全部进行黑盒打包处理。
- 看到任何名词的左边有一大坨句子,直接打个括号 [ ],把它当成一个长长的定语从句,忽略它的内部细节,告诉自己这只是个形容词。
- 看到 から、て、たら、ため,直接在它后面画一条竖线 |,告诉自己这是一个模块化的状语触发器。
💻 实战演示
我们拿一句典型的带有各种嵌套的日企工作长句来跑一次算法:
「昨日チーム会議で激しく議論されたその新しいデザイン案が、今朝のテスト環境で致命的なバグを引き起こしたため、リリースを延期せざるを得なかった。」
1. 直奔句号(锁定主函数):
末尾是 延期せざるを得なかった。
剥去情绪外壳 ざるを得なかった(不得不的过去式)。
核心主函数裸露:延期する(延期)。这是一个他动词(主宾谓结构)。
2. Fetch 参数(找主宾):
向左寻找 を,找到了 リリースを(发布)。
向左找主语,省略了,脑补为“我们”。
核心主干提炼出炉:我们延期了发布。 (到这里,哪怕前面的单词全不认识,你也不会做错阅读理解题。)
3. 碎片打包:
找逻辑控制器:看到了 ため(因为)。这说明 ため 前面的整座大山,全都是导致“延期发布”的原因状语从句。
切入原因从句内部抓主干:デザイン案が (主) + バグを (宾) + 引き起こした (谓)。子主干是:设计案引发了Bug。
剩下的继续打包:名词 デザイン案 左边跟着 昨日チーム会議で激しく議論されたその新しい,全都是修饰它的私有定语从句,一眼跳过。今朝のテスト環境で 是修饰引发 Bug 的时间地点状语,跳过。
最终破解输出:
[原因状语从句:[昨天讨论的] 设计案 引发了 Bug] ——> 触发主干 ——> 我们延期了发布。
原本混沌的长句,瞬间变成了逻辑严密的结构化代码。
第三章 高级语法入门(指针与权限控制)
掌握了基本句型和长难句破解法,你已经击败了 80% 的学习者。剩下 20% 最让人头疼的高级语法无非是:使役、被动、授受动词、敬语。
在传统的教学里,它们被当作令人抓狂的固定搭配死记硬背。但在极客的视野里,它们其实根本不是什么新句型,它们是对底层变量进行了“指针重定向”和“系统权限控制”。
一、 使役与被动(指针重定向)
1. 是什么?
它们是改变原有主谓宾结构中“动作执行者”和“承受者”对应关系的重定向机制。
2. 为什么要有这种机制?
当我们不想提执行者(被动),或者想强调“是谁赋予了执行者权限、是谁逼谁干的”(使役)时,默认的指针映射(が 发出,を/に 承受)就不够用了。我们需要从语法层面反转或降级指针。
3. 怎么分类?
- 被动 (Passive) ~れる/られる:
- 底层逻辑: 指针反转。原本的宾语提拔成了主语(接 が),原本的主语被降级成了补语(加上 に / によって)。
- 示例: 先生が 私を 褒める。 -> 私が 先生に 褒められる。
- 使役 (Causative) ~せる/させる:
- 底层逻辑: 强行在外部增加一个“Root 权限(使役者)”。原本的主语降级成了打工人(接 に 或 を),逼迫他干活的 Boss 成了全新的主语。原本的自动词被迫变成了二项动词。
- 示例: 私が 走る。 -> 社長が 私を 走らせる。(老板让我跑。)
二、 授受关系(Relative Pointers / 相对指针)
1. 是什么?
这是日语独有的、专门用于描述“物品或动作恩惠”在人际网络中转移方向的动词群(あげる、くれる、もらう)。
2. 为什么?
这是大部分初学者的坟墓。因为英语里 give 和 receive 两个词就完事了,为什么日语要搞出三个词?
原因在于,日本文化的底层协议里有一套极其森严的防火墙——“内 (Uchi)” 与 “外 (Soto)”。在日语网络里,传递一个苹果,不仅仅是物理位移,这是一次跨越防火墙的数据请求。日语必须通过动词本身,硬编码标明数据的流动方向!
3. 怎么分类?
(置信度:100%解决所有授受方向混淆问题)
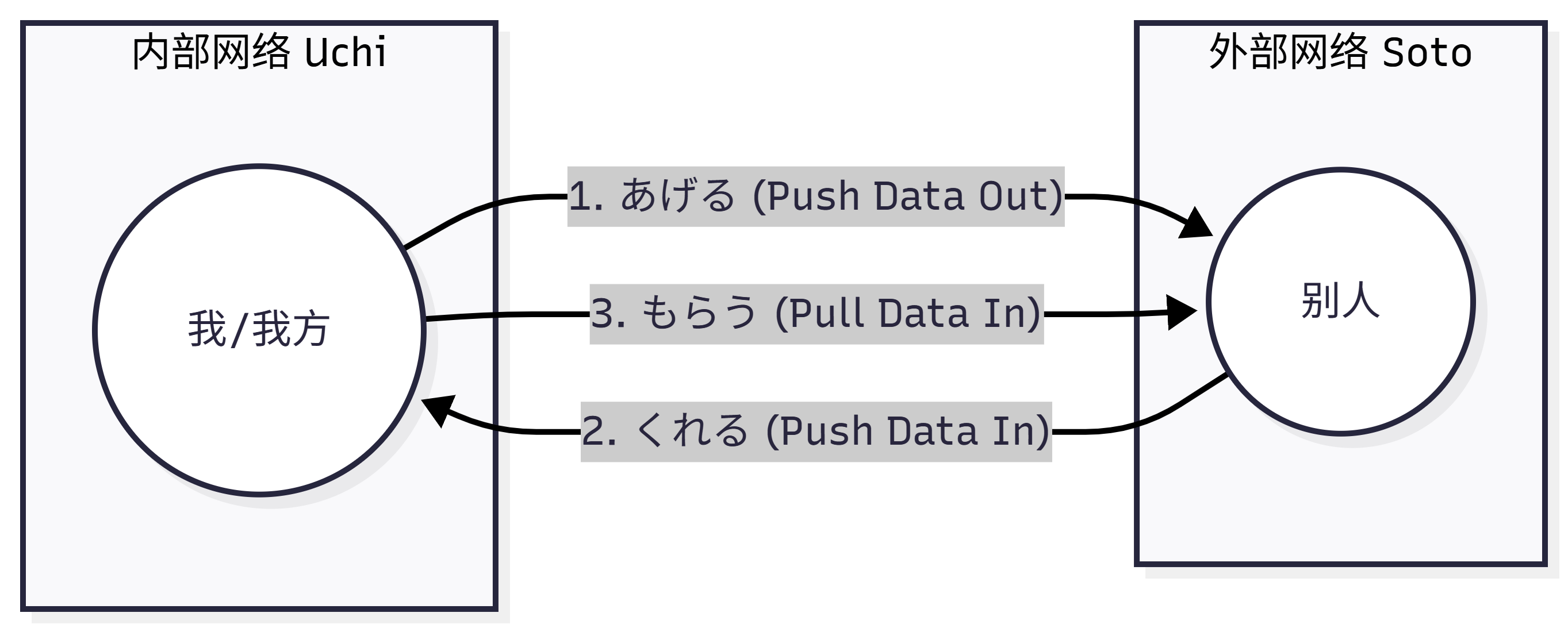
- ① あげる (Ageru): 数据向外层 Push。
- 逻辑: 我或我方,给别人东西。主语必定是我/我方。
- 示例: 私が 友達に 本を あげた。
- ② くれる (Kureru): 数据从外层向内层 Push (External Initiated)。
- 逻辑: 别人给我或我方东西。主语必定是别人!
- 示例: 友達が 私に 本を くれた。
- ③ もらう (Morau): 数据从外层流入内层,但由内层主动发起 Pull 请求。
- 逻辑: 我从别人那里得到东西。主语必定是我。
- 示例: 私が 友達に(から) 本を もらった。
(注:把这三个词接在动词的 て形 后面,传递的就不再是物理物品,而是“动作带来的恩惠”。底层流向逻辑依然坚如磐石。)
三、 敬语体系(Access Control List / 权限控制)
1. 是什么?
敬语(Keigo)根本不是什么玄学,它就是一套直接硬编码在动词词尾、或通过特殊词汇替换实现的访问控制列表(ACL)。
2. 为什么?
日本社会极度强调阶级关系和读空气(KY)。在不同的运行环境里(对面是长辈、平级、客户还是公众),如果越权调用了底层函数,会导致严重的 Social Crash。因此,语法设计者干脆把权限验证做成了一套外壳(Decorator)套在谓语上。
3. 怎么分类?
这套权限控制体系极其庞大,但分类严谨(置信度:涵盖现代日语所有标准化敬语调用法则):

- ① 尊敬语 (Admin Override / 抬高对方): 赋予动作主体最高权限。绝对不能用于描述自己的动作!
- 具体形态:
- 特殊底层替换: 比如 食べる 直接替换为 召し上がる,行く 替换为 いらっしゃる。
- 轻量级封装(被动形): 直接借用被动语态的 ~れる/られる,如 社長が来られる。(利用被动语态拉开距离,产生敬意)。
- 标准外壳嵌套: お/ご + 动词连用形 + になる。如 お読みになる。
- 请求接口调用: お/ご + 动词连用形 + ください。如 お待ちください。
- 具体形态:
- ② 谦让语 (Guest Mode / 压低自己): 降低自身权限,以此衬托对方。只用于描述自己或己方成员的动作!
- 具体形态:
- 特殊底层替换: 見る 降级为 拝見する,聞く 降级为 伺う。
- 标准外壳嵌套: お/ご + 动词连用形 + する/いたす。如 お持ちする。
- 具体形态:
- ③ 丁重语 (System Log Level): 谦让语的一种变体。压低自己,但动作并没有直接承受的尊贵对象(只是陈述客观行为)。
- 具体形态: 行く 说成 参る,言う 说成 申す。
- ④ 丁宁语 (Public API / 格式化输出): 不改变动作的内外权限,纯粹是为了在公共环境下对听众保持基本的体面。
- 具体形态: です、ます、ございます。
💡 实战黑客技巧(极其重要):
这套权限控制不仅是为了礼貌,在长难句阅读中,敬语往往承担了“隐形指针”的神级功能!
由于日语经常省略主语,如果你在句末看到一个“尊敬语”外壳(如 ~いらっしゃる),不用想,这个动作绝对不是“我”发出的,肯定是高级别权限对象(客户/老板)发出的。反之,如果看到“谦让语”(如 拝見する),那不管句子有多长,动作执行者必定是“我方”。
敬语填补了省略带来的信息黑洞,这就是高语境网络独有的参数恢复机制。
后记
圣经《箴言》25章2节中写道:
“将事隐秘,乃神的荣耀。将事察清,乃君王的荣耀。”
学习一门外语,去破解那些长难句,其实就是一个“将事察清”的逆向工程过程。
面对纷繁复杂的表象和反直觉的语序,如果我们只停留在死记硬背单词和“N1必考语法100条”上,那我们就是在被动地应对无尽的补丁。而当我们尝试去拆解这门语言的词类参数、基本句型骨架、从句的封装模式以及剥洋葱的解析算法时,我们就仿佛掌握了某种底层源码,拥有了“造物主”般的全局视野。
写这篇文章,一方面是为了梳理我脑海中关于日语那些“看起来反人类,实则逻辑极其严密”的架构体系。另一方面,也是作为对之前那篇《破解英语长难句入门指南》的一种印证与补完。从英语的链表拓展,到日语的洋葱包裹,虽然两门语言的数据结构截然不同,但运用极客思维去解构它们,带来的“Aha Moment”是相同的。
这篇文章里的许多命名和划分规则(比如四大动词引擎、剥洋葱算法),是我为了优化认知负荷、提升实战效率而自行构建的“私有框架”。它或许不完全符合最刻板的传统文法书,但它在实战阅读与架构拆解中,跑出了极高的通关率。
希望这篇笔记,能为那些深陷日语长难句泥潭、厌倦了死记硬背的朋友,提供一种全新的解码思路。
Code the language, don't just memorize it.